
Diagnosing Multi-step Reasoning Failures in Black-box LLMs via Stepwise Confidence Attribution
Xiaoou Liu, Tiejin Chen, Dengjia Zhang, Yaqing Wang, Lu Cheng, Hua Wei
ICML’26
[Paper] [Github]
TL;DR
LLMs generate step-by-step reasoning traces, but figuring out where in that chain a mistake happens is hard, especially when you can’t access to the model. We introduce Stepwise Confidence Attribution (SCA), a framework that assigns confidence to each reasoning step using only the generated text. Steps that align with consensus structures across correct solutions get high confidence; deviations are flagged as potentially erroneous.
Motivation
Large Language Models have achieved strong performance on reasoning tasks by generating step-by-step solutions. But when a multi-step trace goes wrong, diagnosing which step failed remains difficult. Existing confidence estimation methods are either restricted to final answers or require access to model internals. For closed-source models accessed via APIs, which is how most people use frontier LLMs, neither option is available.
We need a method that works with black-box models, using only the generated reasoning traces as input.
Our Approach: Stepwise Confidence Attribution (SCA)
SCA applies the Information Bottleneck (IB) principle to reasoning traces. The core insight: if a reasoning step consistently appears across multiple correct solution paths, it is likely a reliable step. Steps that deviate from this consensus structure are flagged as potentially erroneous.
We propose two complementary methods:
NIBS: Non-parametric IB for Step Confidence
NIBS measures the consistency of each step against a set of sampled correct solutions, without building any graph structure. It directly scores how well a step aligns with the consensus reasoning pattern.
GIBS: Graph-based IB for Step Confidence
GIBS goes further by constructing a graph representation of reasoning traces and learning subgraphs through a differentiable mask. This captures logical variability and structural dependencies between steps that NIBS might miss.
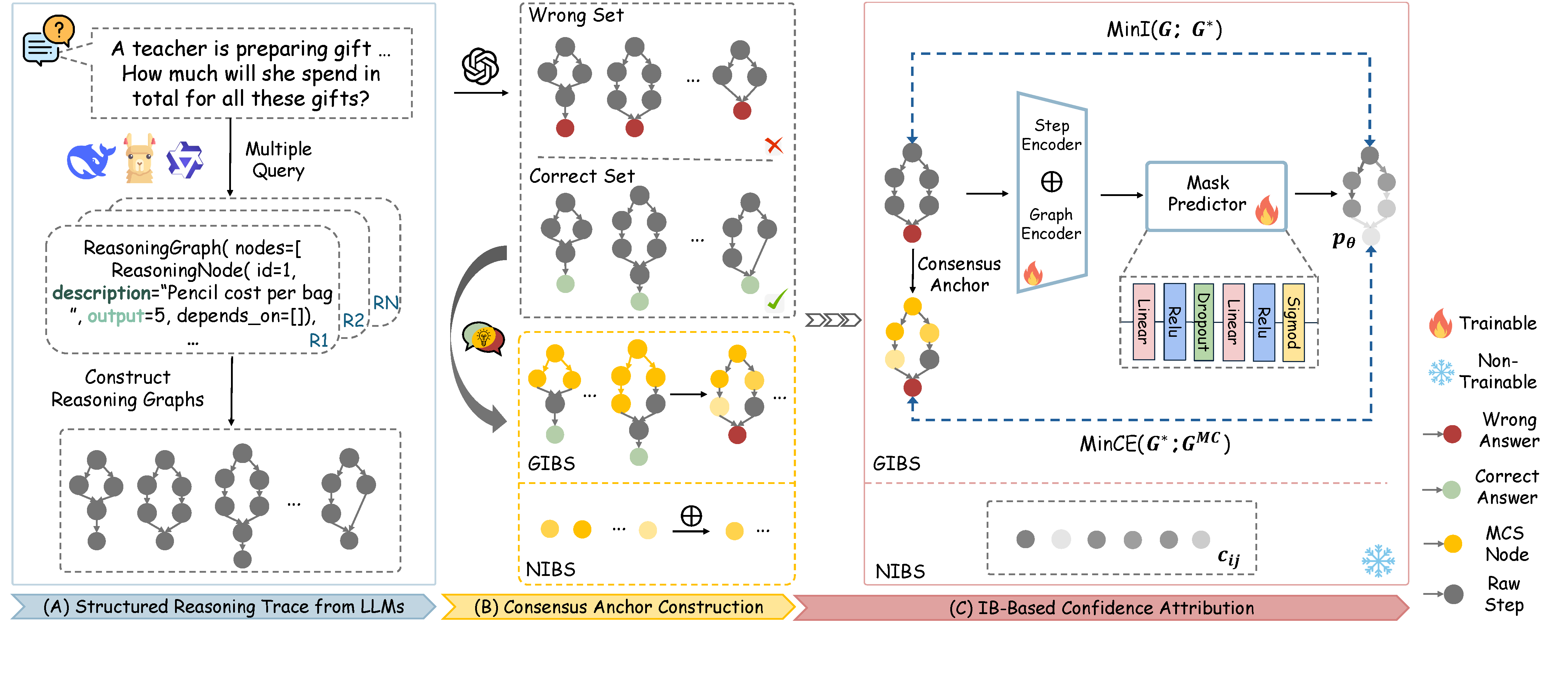 Overview of the Stepwise Confidence Attribution (SCA) framework.
Overview of the Stepwise Confidence Attribution (SCA) framework.
Key Results
Accurate Error Detection: Both NIBS and GIBS significantly outperform strong baselines at identifying erroneous steps in reasoning traces.
Improved Self-Correction: The stepwise confidence scores can be fed back to the LLM to guide targeted self-correction, improving final-answer accuracy.
Robustness: The framework generalizes well across different reasoning formats, works without final-answer labels, and handles domain shift effectively.
Takeaway
You don’t need to open the black box to diagnose reasoning failures. By using the Information Bottleneck principle on generated traces, SCA provides step-level confidence estimation that is accurate, useful for self-correction, and applicable to any closed-source LLM.