
The Sim-to-Real Gap of Foundation Model Agents: A Unified MDP Perspective
Xiaoou Liu*, Tiejin Chen*, Weibo Li, Xiyang Hu, Hua Wei
KDD’26 Blue Sky Track
[Paper]
TL;DR
Foundation model agents often look impressive on benchmarks yet stumble in real deployment. This is not a new mystery but a form of the classic sim-to-real gap long studied in reinforcement learning. By formalizing both benchmarks and deployment within a unified MDP framework, we identify four channels through which this gap emerges and connect each channel to established remedies.
Motivation
An LLM agent today does more than chat: it calls tools, reads results, and takes actions to finish tasks. These agents achieve high scores on tidy benchmarks where inputs are clean and failures are cost-free. However, in deployment, they face noisy multilingual requests, tools that time out or return malformed data, and real costs in money and latency. A high leaderboard score says little about whether an agent will hold up in the wild.
The community keeps encountering these failures one at a time, but lacks a shared vocabulary for discussing them. We propose to change that.
Key Idea: Four MDP Channels
Reinforcement learning calls this the sim-to-real gap, which is the performance drop when a policy trained in simulation meets the messier real world. We bridge this to LLM agents by describing both settings with a Markov Decision Process (MDP). The four core elements, Observation, Action, Transition, and Reward, define four channels through which the gap can emerge:
Observation Gap. The agent’s inputs drift through typos, paraphrases, or language switches. This is the perception mismatch that robotics handles with domain randomization and adaptation.
Action Gap. The set of available tools is crowded with near-duplicate or distracting options, answered by action shielding that filters unsafe or invalid calls.
Transition Gap. Tools time out or return broken responses — the dynamics mismatch addressed by grounding methods that make simulated tools behave like real ones.
Reward Gap. A plain accuracy score ignores hidden fees and latency. Reward shaping and augmentation can fold these real-world costs back in.
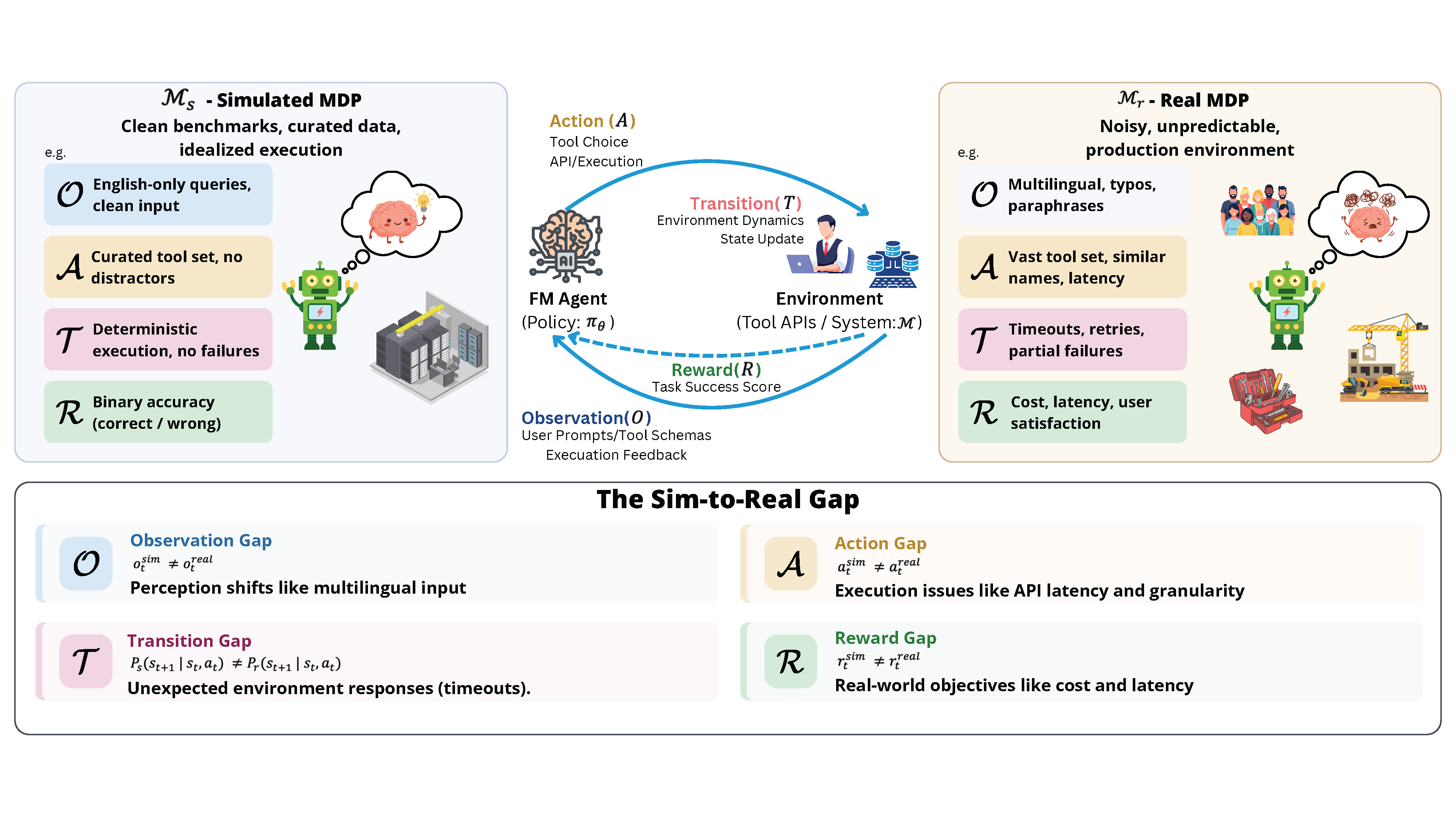 Overview of the four MDP channels through which the sim-to-real gap manifests in foundation model agents.
Overview of the four MDP channels through which the sim-to-real gap manifests in foundation model agents.
Research Agenda
Reading the gap through these four channels suggests a concrete research program:
- Build stress-test benchmarks that inject controlled noise into each channel, rather than testing only on clean inputs.
- Share perturbation recipes so results are comparable across groups.
- Design training that randomizes these conditions so robustness is learned rather than hoped for.
Takeaway
Agent robustness already has a science behind it. Naming the failure as a sim-to-real gap over four MDP channels gives the community one shared language, a set of ready remedies, and an honest way to measure trustworthiness before deployment.